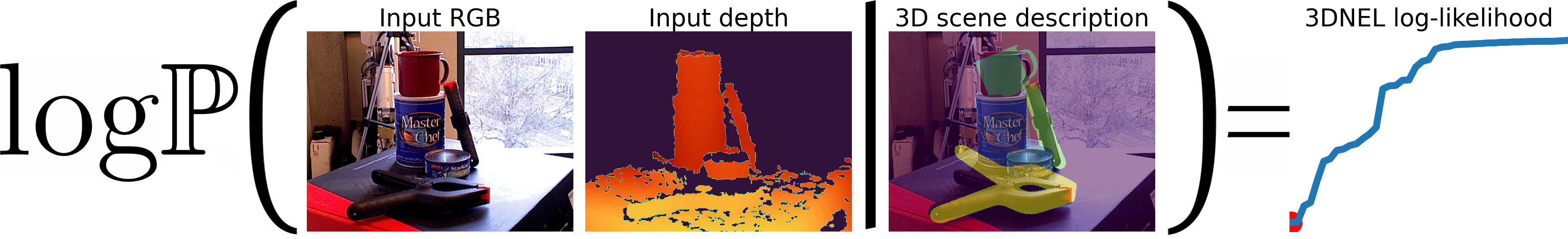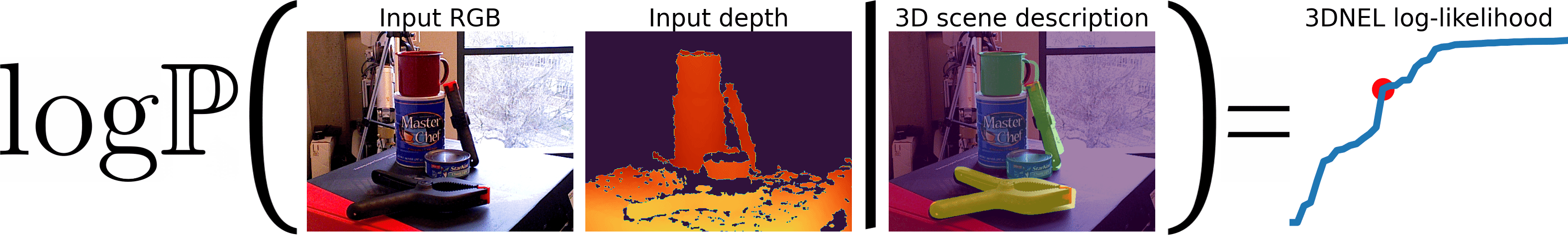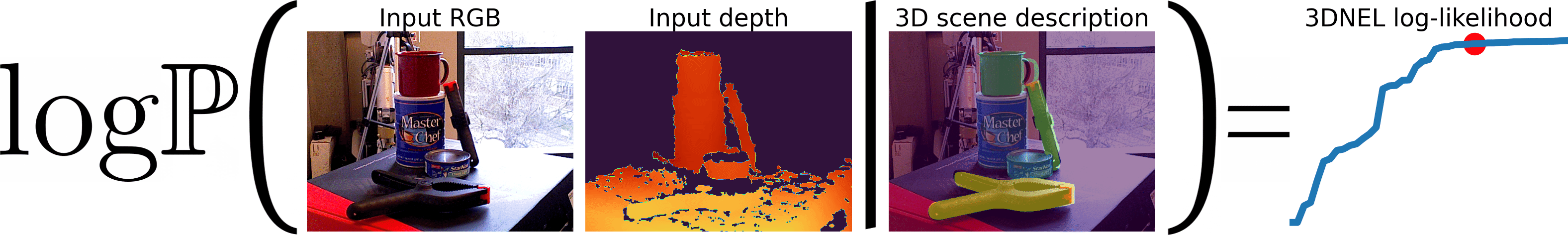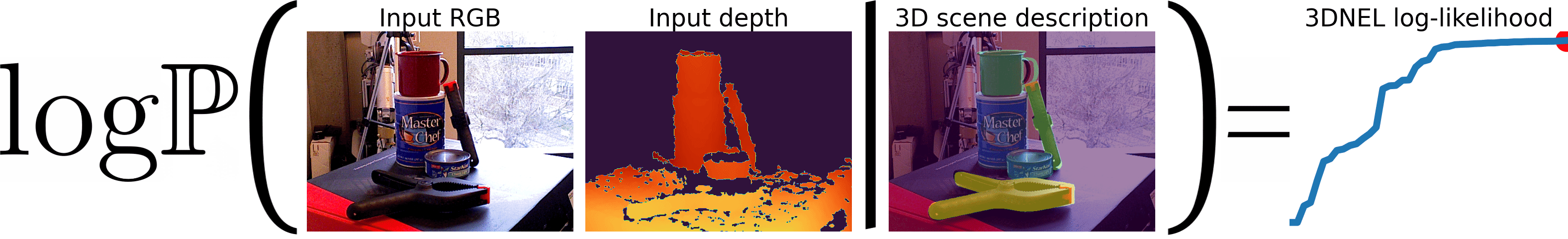
3D Neural Embedding Likelihood (3DNEL)
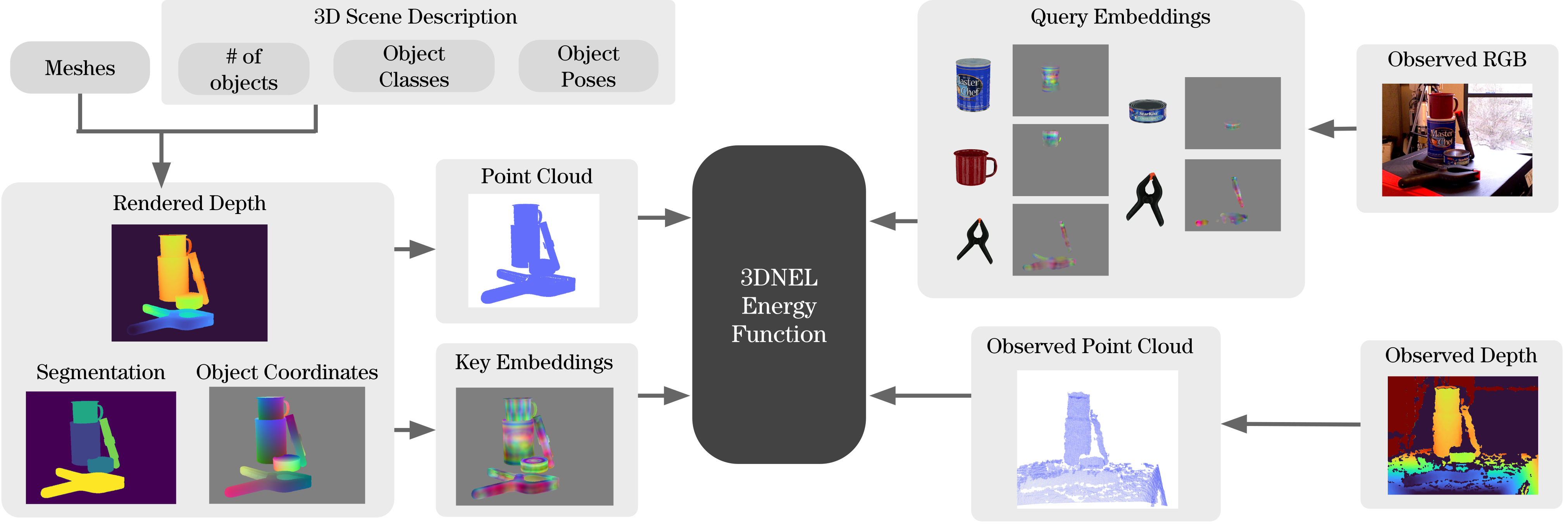
3DNEL defines the probability of an observed RGB-D image conditioned on a 3D scene description. We first render the 3D scene description into: (1) a depth image, which is transformed to a rendered point cloud image, (2) a semantic segmentation map, and (3) the object coordinate image (each pixel contains the object frame coordinate of the object surface point from which the pixel originates). The object coordinate image is transformed, via the key models, into key embeddings. The observed RGB image is transformed, via the query models, into query embeddings. The observed depth is transformed into an observed point cloud image. The 3DNEL Energy Function is evaluated using the rendered point cloud image, semantic segmentation, key embeddings, the observed point cloud image, and query embeddings.